PRML 9장 EM 알고리즘 완전분석A Step by Step Introduction to EM Algorithm; Pattern Recognition and Machine Learning - Chap. 9
이전 K-means 클러스터링 글을 포스팅하면서 곧 EM 알고리즘 글을 포스팅하려 했는데 여러 사정으로 무려 1년이 지나버렸다. 더 이상 미뤄선 안되겠다는 생각이 들어 정말 오랜만에 블로그에 포스팅을 하기로 했다.
머신러닝을 공부하다 보면 한번은 보게되는 알고리즘이 바로 EM 알고리즘인데 이해하기가 쉽지 않아 볼 때마다 답답함을 느끼는 분들이 많을 것이다.(아닌가? 나만 답답하나?) 많은 문헌에서 이 알고리즘을 설명할 때 K-평균 군집화로 시작해서 가우시안 혼합으로 끝을 맺는다. 하지만 두 알고리즘에 대해서 설명하는 것은 EM 알고리즘의 적용 예를 설명하는 것이지 EM 알고리즘을 근본적으로 이해하기 위한 논리를 설명하는 것이 아니어서 해당 내용을 모두 읽어봐도 EM 알고리즘이 도대체 무엇인지 감을 잡기 힘든 경우가 대부분이다.
이런 이유로 EM 알고리즘을 제대로 이해할 수 있도록 PRML 9장 내용을 상세히 풀어적었다. 글은 EM 알고리즘의 핵심 내용인 아래 그림을 완전히 이해하기 위해 총 4편으로 구성 되어 있다.
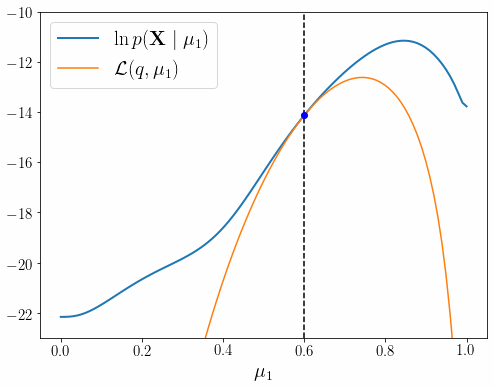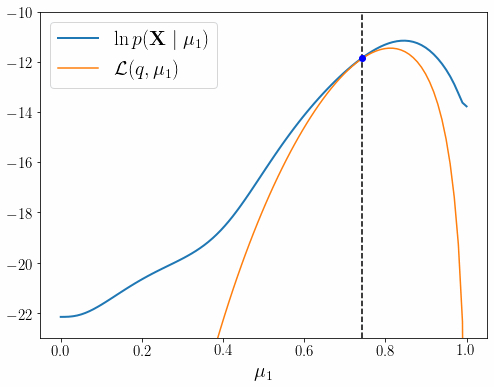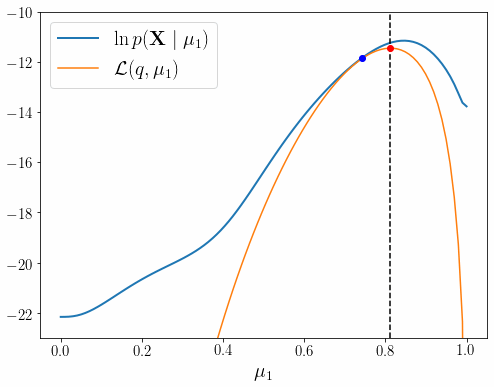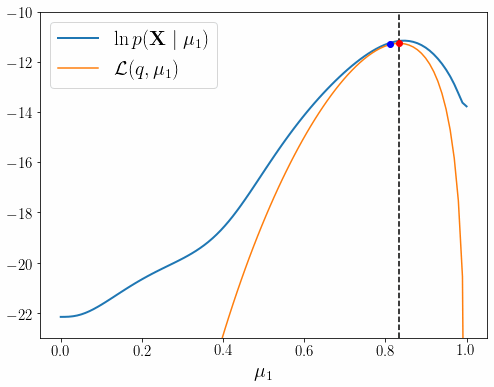
각 장의 내용은 아래와 같다.
- 완전 데이터 세트에 대한 최대 가능도 추정
- 불완전 데이터 세트에 대한 최대 가능도 추정
- 기댓값-최대화 반복과정에 대한 설명
- 수렴에 대한 이유
평소 EM 알고리즘에 대해 조금 찝찝함이 남아있던 분들은 한번 읽어보면 많은 도임이 되리라 생각한다.
글에 등장하는 수식은 모두 PRML에 나온 식들이며 이해를 돕기위해 식번호를 동일하게 매겼다. 전체 글은 Google Colab으로 작성되어 있어서 아래 링크로 Colab을 통해 공유하므로 본인의 구글 드라이브로 복사하여 바로 바로 코드를 실행하면서 글을 읽을 수 있게 하였다.
![]() EM 알고리즘 이해하러 가기
EM 알고리즘 이해하러 가기