import numpy as np
import matplotlib.pyplot as plt
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from tqdm import tqdm
import plotly.io
import plotly.graph_objects as go
# colab: coloab
# jupyter lab: jupyterlab
# jupyter notebook, quarto blog: notebook
plotly.io.renderers.default = "notebook"친절한 디퓨전 모델 2-2편: DDPM 실습 파이토치편
이전 글에서 DDPM에 대한 이론을 자세히 알아 봤습니다. 2-1편에 이어 2-2편에서는 파이토치를 사용해서 DDPM 모델을 직접 만들어봅니다. DDPM을 구현한 많은 참고 자료들이 인터넷에 많으나 이론에 나오는 수식을 1:1 방식으로 간결하게 코드로 매치 시키는 구현은 찾아보기 힘듭니다. DDPM 공식 구현 코드도 간결하고 읽기 좋게 작성된 코드는 아닙니다. 좋은 품질의 이미지를 생성하기 위해 복잡한 네트워크 구조를 사용하고 다양한 실험 옵션을 반영하기 때문인데 이런 코드는 학습용 코드로는 부적합 합니다.
이런 이유로 본 글에서는 최소한 납득할 만한 결과를 보여 주면서도 가능한 간단한 구조로 된 모델을 정의해 사용할 것입니다. 이를 통해 쉽고 빠르게 이론과 실제 코드를 연결하여 이해할 수 있도록 구성했습니다. 더 정교한 이미지를 생성하기 위한 복잡한 네트워크의 적용을 독자 여러분의 몫으로 남겨두도록 하겠습니다.
[주의] 이 글은 친절한 디퓨전 모델 1편의 후속 글로 1편을 읽지 않고 읽으면 정확히 이해가 안될 수 있습니다.
이 글에서 사용하는 데이터 셋은 deeplearning.ai에서 제공하는 숏코스 How Diffusion Models Work에서 사용하는 16x16 크기를 가지는 이미지 스프라이트입니다.
이 글은 다음 링크를 통해 구글 코랩에서 직접 실행하며 읽을 수 있습니다.
![]()
# 사용 디바이스 세팅
device = 'cuda' if torch.cuda.is_available() else 'cpu'
device'cuda'데이터 셋 준비
가정 먼저 준비된 데이터 셋 파일을 다운 받습니다.
!gdown 1gADYmo2UXlr24dUUNaqyPF2LZXk1HhrJ데이터 파일이 넘파이 어레이로 구성되어 있으므로 np.load()로 로딩합니다.
sprites = np.load('sprites_1788_16x16.npy')데이터 셋은 넘파이 어레이이며 데이터 셋의 모양과 각 샘플의 최솟값, 최댓값을 확인해보면 개별 샘플은 모양이 (16,16,3)이고 0에서 255값을 가지는 이미지 어레이라는 것을 알 수 있습니다.
sprites.shape, sprites.min(), sprites.max()((89400, 16, 16, 3), 0, 255)이미지의 크기와 채널수를 설정합니다.
H = 16
W = 16
C = 3노이즈 스케쥴러 정의 및 적용
이미지를 한장씩 반환하는 데이터셋 클래스 MyDataset을 정의 합니다. 데이터셋 내부에서 이미지에 대한 일련의 transform을 적용하고 나서 노이즈 추가을 진행하기 위해 식(4)에서 사용하는 \(\beta_t\), \(\alpha_t\), \(\bar\alpha_t\)를 클래스 변수로 계산해 둡니다.
class MyDataset(Dataset):
# beta는 DDPM 원문의 설정을 따르고
beta_1 = 1e-4
beta_T = 0.02
# 시간 단계는 deeplearning.ai에서 제공하는 숏코스 How Diffusion Models Work의 설정을 따름
T = 500
# beta는 첨자 1부터 T까지 사용하기 위해 제일 앞에 더미 데이터 tf.constant([0.])를 추가하여 만듬
beta = torch.cat([ torch.tensor([0]), torch.linspace(beta_1, beta_T, T)], axis=0)
alpha = 1 - beta
alpha_bar = torch.exp(torch.cumsum(torch.log(alpha), axis=0))
def __init__(self, data, transform=None):
self.data = data
self.transform = transform
def __len__(self):
return self.data.shape[0]
def __getitem__(self, i):
x_0 = self.data[i]
# normalize -1~1로 만들기
if self.transform:
x_0 = self.transform(x_0)
# noise 추가
t = np.random.randint(1, MyDataset.T+1)
eps = torch.randn_like(x_0)
x_t = torch.sqrt(MyDataset.alpha_bar[t]) * x_0 + torch.sqrt(1 - MyDataset.alpha_bar[t]) * eps
return x_0, x_t, eps, t이미지 픽셀값을 -1~1사이로 변환하는 transform을 구성하고 데이터 셋을 생성합니다. 계속해서 생성된 데이터 셋을 이용하는 데이터 로더도 준비합니다. 배치사이즈는 텐서플로 구현과 같게 64로 지정합니다.
transform = transforms.Compose([
transforms.ToTensor(), # from [0,255] to range [0.0, 1.0]
transforms.Normalize((0.5,), (0.5,)) # range [-1,1]
])
train_ds = MyDataset(sprites, transform)
m = 64
train_loader = DataLoader(train_ds, batch_size=m, shuffle=True)
train_loader_iter = iter(train_loader)데이터 로더로 부터 미니배치를 받아와 그림을 그려봅니다.
samples = next(train_loader_iter)
x_0s = samples[0][:6].numpy()
x_ts = samples[1][:6].numpy()
epss = samples[2][:6].numpy()
ts = samples[3][:6].numpy()fig, axs = plt.subplots(figsize=(10,5), nrows=3, ncols=6)
i = 0
for (x_0, x_t, eps, t) in zip(x_0s, x_ts, epss, ts):
x_0 = x_0.transpose(1,2,0)
x_0 = ((x_0 - x_0.min()) / (x_0.max() - x_0.min())).clip(0,1)
axs[0][i].imshow(x_0)
axs[0][i].set_title(f"t={t}")
axs[0][i].set_xticks([])
axs[0][i].set_yticks([])
eps = eps.transpose(1,2,0)
eps = ((eps - eps.min()) / (eps.max() - eps.min())).clip(0,1)
axs[1][i].imshow(eps)
axs[1][i].set_xticks([])
axs[1][i].set_yticks([])
x_t = x_t.transpose(1,2,0)
x_t = ((x_t - x_t.min()) / (x_t.max() - x_t.min())).clip(0,1)
axs[2][i].imshow(x_t)
axs[2][i].set_xticks([])
axs[2][i].set_yticks([])
if i == 0:
axs[0][i].set_ylabel('x_0')
axs[1][i].set_ylabel('eps')
axs[2][i].set_ylabel('x_t')
i += 1
plt.show()
그림을 확인해보면 샘플 중 앞 여섯개에 임의의 시간 단계에 대한 노이즈가 적용되는 것을 알 수 있습니다. 첫 행은 원본 이미지, 둘째 행은 적용될 노이즈, 셋째 행은 노이즈가 적용된 모습을 나타냅니다. 시간 단계가 작을 수록 원본 이미지가 남아있고 200이 넘어가면 거의 알아볼 수 없게 될 것입니다.
만들어진 데이터 셋에 셔플과 배치사이즈를 적용합니다.
모델 만들기
이제 모델을 정의 합니다. 가능하다면 (3,16,16) 크기의 이미지를 (768,) 크기의 벡터로 펼친 다음 완전 연결 네트워크로만 구성하고 싶었지만 실험 결과 이런 MLP 구조로는 의미있는 결과를 만들 수 없었습니다. 따라서 conv 레이어를 가지는 간단한 네트워크를 사용합니다. 원문에는 Unet 구조를 사용한다고 되어있지만 Unet도 복잡하기 때문에 Unet 특징이 약간 들어있는 아래 그림과 같은 네트워크를 사용하겠습니다.
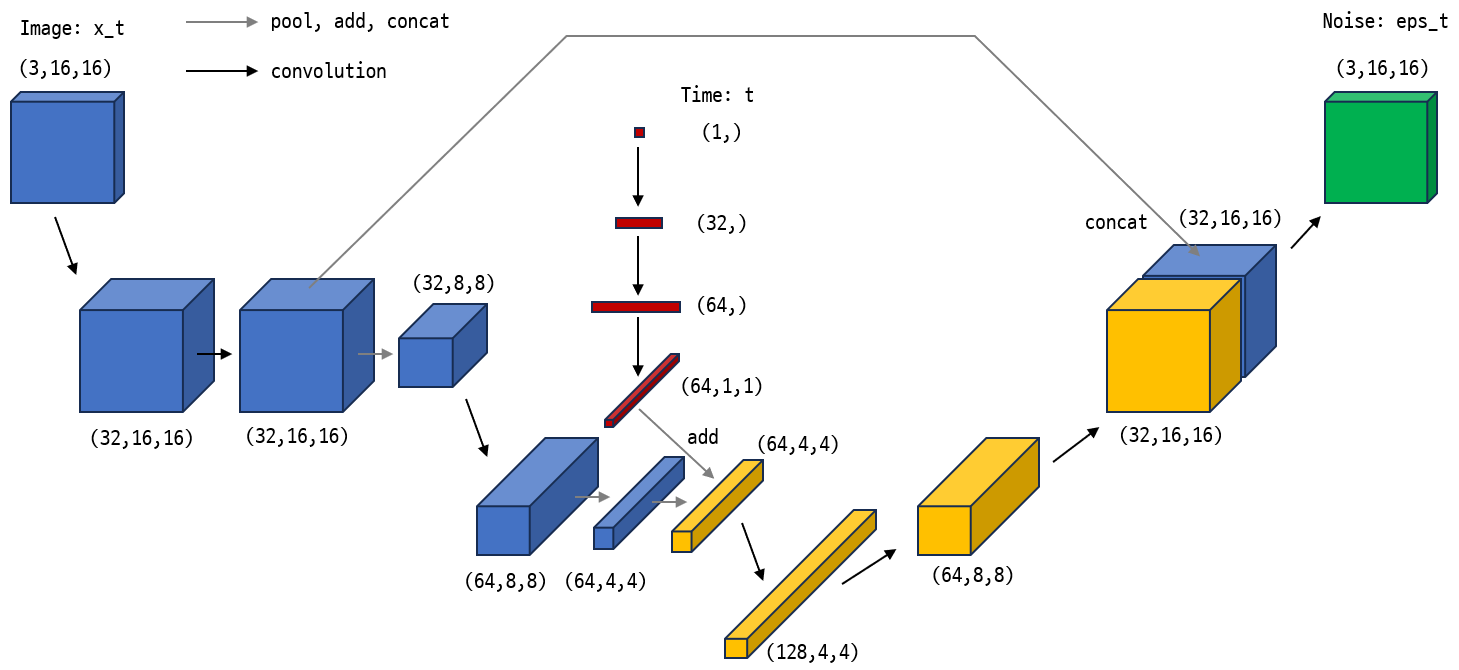
네트워크 구조는 매우 간단하여 그림과 아래 코드를 함께 보면 금방 이해가 갈 것입니다. 네트워크의 특징을 다음으로 요약할 수 있습니다.
이미지에 Conv레이어를 몇번 적용하여 만들어진 특징 맵과 시간 단계에 Dense 레이어를 몇번 적용한 임베딩 벡터를 중간쯤에서 더하여 두 입력을 모두 반영하는 특징 맵을 만듭니다.
특징 맵을 다시 이미지 모양으로 디코딩할 때 인코딩 과정에서 만들어 둔 특징 맵과 연결시키는 스킵 커넥션 구조를 한번 사용합니다.
class DDPM(torch.nn.Module):
def __init__(self):
super().__init__()
self.emb_1 = torch.nn.Linear(in_features=1, out_features=32)
self.emb_2 = torch.nn.Linear(in_features=32, out_features=64)
self.down_conv1_32 = torch.nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, padding=1)
self.down_conv2_32 = torch.nn.Conv2d(in_channels=32, out_channels=32, kernel_size=3, padding=1)
self.down_conv3_64 = torch.nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, padding=1)
self.down_conv4_128 = torch.nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, padding=1)
self.up_conv1_64 = torch.nn.ConvTranspose2d(in_channels=128, out_channels=64, kernel_size=3, stride=2, padding=1)
self.up_conv2_32 = torch.nn.ConvTranspose2d(in_channels=64, out_channels=32, kernel_size=3, stride=2, padding=1)
self.up_conv3_32 = torch.nn.Conv2d(in_channels=64, out_channels=3, kernel_size=3, padding=1)
self.relu = torch.nn.ReLU()
self.gelu = torch.nn.GELU()
def forward(self, x, t):
# x: (N, C, H, W)
# t: (N,1)
batch_size = t.shape[0]
# time embedding
t = self.relu( self.emb_1(t) ) # (N, 32)
t = self.relu( self.emb_2(t) ) # (N, 64)
t = t.reshape(batch_size, -1, 1, 1) # (N, 64, 1, 1)
# image down conv
x = self.gelu( self.down_conv1_32(x) ) # (N, 32, 16, 16)
x_32 = self.gelu( self.down_conv2_32(x) ) # (N, 32, 16, 16)
size_32 = x_32.shape
x = torch.nn.functional.max_pool2d(x_32, (2,2)) # (N, 32, 8, 8)
x = self.gelu( self.down_conv3_64(x) ) # (N, 64, 8, 8)
size_64 = x.shape
x = torch.nn.functional.max_pool2d(x, (2,2)) # (N, 64, 4, 4)
x = x + t # (N, 64, 4, 4) + (N, 64, 1, 1) = (N, 64, 4, 4)
x = self.gelu( self.down_conv4_128(x) ) # (N, 128, 4, 4)
# image up conv
x = self.gelu( self.up_conv1_64(x, output_size=size_64) ) # (N, 64, 8, 8)
x = self.gelu( self.up_conv2_32(x, output_size=size_32) ) # (N, 32, 16, 16)
x = torch.concat([x, x_32], axis=1) # (N, 64, 16, 16)
out = self.up_conv3_32(x) # (N, 3, 16, 16)
return out모델을 만들고 사용 다바이스로 모델을 이동시킵니다.
model = DDPM()
model.to(device)DDPM(
(emb_1): Linear(in_features=1, out_features=32, bias=True)
(emb_2): Linear(in_features=32, out_features=64, bias=True)
(down_conv1_32): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(down_conv2_32): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(down_conv3_64): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(down_conv4_128): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(up_conv1_64): ConvTranspose2d(128, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(up_conv2_32): ConvTranspose2d(64, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(up_conv3_32): Conv2d(64, 3, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(relu): ReLU()
(gelu): GELU(approximate='none')
)모델을 완성했으면 앞서 만들어둔 데이터 셋을 이용해 포워드 테스트를 해봐야 합니다. 배치 사이즈 64이므로 한 배치를 네트워크에 입력하면 출력으로 (64,3,16,16)이 나와야 합니다.
output = model(samples[0].to(device), samples[3].reshape(-1,1).float().to(device))
print(output.shape)torch.Size([64, 3, 16, 16])포워드 테스트가 성공했으므로 이제 학습 시키는 일만 남았습니다.
학습
\[ L_{\text{simple}}(\theta) := \mathbb{E}_{t, \mathbf{x}_0, \boldsymbol{\epsilon}} \left[ \left\lVert \boldsymbol{\epsilon}- \boldsymbol{\epsilon}_\theta(\sqrt{\bar\alpha_t}\mathbf{x}_0 + \sqrt{1-\bar\alpha_t}\boldsymbol{\epsilon}, t) \right\rVert^2_2 \right] \tag{14} \]
위 손실 함수는 모든 샘플과 시간 단계에 대해서 MSE 손실 함수를 사용한다는 것을 의미합니다. 손실 함수를 식(14)처럼 MSE로 설정하고 적당한 옵티마이저를 생성합니다.
loss_func = torch.nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.0001)다음은 학습 루프를 구현할 차례입니다.

위 그림에 나타난 학습 알고리즘을 직접 구현합니다. 학습 루프에서 mae 매트릭도 함께 계산해서 화면에 출력해 줍니다.
epochs = 30
losses = []
for e in range(epochs):
epoch_loss = 0.0
epoch_mae = 0.0
for i, data in enumerate(tqdm(train_loader)):
x_0, x_t, eps, t = data
x_t = x_t.to(device)
eps = eps.to(device)
t = t.to(device)
optimizer.zero_grad()
eps_theta = model(x_t, t.reshape(-1,1).float())
loss = loss_func(eps_theta, eps)
loss.backward()
optimizer.step()
with torch.no_grad():
epoch_loss += loss.item()
epoch_mae += torch.nn.functional.l1_loss(eps_theta, eps)
epoch_loss /= len(train_loader)
epoch_mae /= len(train_loader)
print(f"Epoch: {e+1:2d}: loss:{epoch_loss:.4f}, mae:{epoch_mae:.4f}")
losses.append(epoch_loss)100%|██████████████████████████████████████████████████████████████████████████| 1397/1397 [00:07<00:00, 193.73it/s]
100%|██████████████████████████████████████████████████████████████████████████| 1397/1397 [00:06<00:00, 202.67it/s]
100%|██████████████████████████████████████████████████████████████████████████| 1397/1397 [00:07<00:00, 199.00it/s]
100%|██████████████████████████████████████████████████████████████████████████| 1397/1397 [00:06<00:00, 204.76it/s]
100%|██████████████████████████████████████████████████████████████████████████| 1397/1397 [00:06<00:00, 205.65it/s]
100%|██████████████████████████████████████████████████████████████████████████| 1397/1397 [00:06<00:00, 202.85it/s]
100%|██████████████████████████████████████████████████████████████████████████| 1397/1397 [00:06<00:00, 208.54it/s]
100%|██████████████████████████████████████████████████████████████████████████| 1397/1397 [00:06<00:00, 207.12it/s]
100%|██████████████████████████████████████████████████████████████████████████| 1397/1397 [00:06<00:00, 205.49it/s]
100%|██████████████████████████████████████████████████████████████████████████| 1397/1397 [00:06<00:00, 208.28it/s]
100%|██████████████████████████████████████████████████████████████████████████| 1397/1397 [00:06<00:00, 205.37it/s]
100%|██████████████████████████████████████████████████████████████████████████| 1397/1397 [00:06<00:00, 206.47it/s]
100%|██████████████████████████████████████████████████████████████████████████| 1397/1397 [00:06<00:00, 204.66it/s]
100%|██████████████████████████████████████████████████████████████████████████| 1397/1397 [00:06<00:00, 205.35it/s]
100%|██████████████████████████████████████████████████████████████████████████| 1397/1397 [00:06<00:00, 205.87it/s]
100%|██████████████████████████████████████████████████████████████████████████| 1397/1397 [00:06<00:00, 201.97it/s]
100%|██████████████████████████████████████████████████████████████████████████| 1397/1397 [00:06<00:00, 208.26it/s]
100%|██████████████████████████████████████████████████████████████████████████| 1397/1397 [00:07<00:00, 199.27it/s]
100%|██████████████████████████████████████████████████████████████████████████| 1397/1397 [00:06<00:00, 206.42it/s]
100%|██████████████████████████████████████████████████████████████████████████| 1397/1397 [00:06<00:00, 199.97it/s]
100%|██████████████████████████████████████████████████████████████████████████| 1397/1397 [00:06<00:00, 202.68it/s]
100%|██████████████████████████████████████████████████████████████████████████| 1397/1397 [00:07<00:00, 198.86it/s]
100%|██████████████████████████████████████████████████████████████████████████| 1397/1397 [00:06<00:00, 199.91it/s]
100%|██████████████████████████████████████████████████████████████████████████| 1397/1397 [00:06<00:00, 203.76it/s]
100%|██████████████████████████████████████████████████████████████████████████| 1397/1397 [00:06<00:00, 208.81it/s]
100%|██████████████████████████████████████████████████████████████████████████| 1397/1397 [00:06<00:00, 207.95it/s]
100%|██████████████████████████████████████████████████████████████████████████| 1397/1397 [00:06<00:00, 205.44it/s]
100%|██████████████████████████████████████████████████████████████████████████| 1397/1397 [00:06<00:00, 207.08it/s]
100%|██████████████████████████████████████████████████████████████████████████| 1397/1397 [00:06<00:00, 204.23it/s]
100%|██████████████████████████████████████████████████████████████████████████| 1397/1397 [00:06<00:00, 202.92it/s]Epoch: 1: loss:0.3821, mae:0.4512
Epoch: 2: loss:0.2485, mae:0.3536
Epoch: 3: loss:0.2037, mae:0.3103
Epoch: 4: loss:0.1852, mae:0.2918
Epoch: 5: loss:0.1719, mae:0.2790
Epoch: 6: loss:0.1661, mae:0.2724
Epoch: 7: loss:0.1602, mae:0.2661
Epoch: 8: loss:0.1550, mae:0.2602
Epoch: 9: loss:0.1530, mae:0.2575
Epoch: 10: loss:0.1504, mae:0.2545
Epoch: 11: loss:0.1468, mae:0.2506
Epoch: 12: loss:0.1451, mae:0.2487
Epoch: 13: loss:0.1425, mae:0.2459
Epoch: 14: loss:0.1414, mae:0.2445
Epoch: 15: loss:0.1385, mae:0.2418
Epoch: 16: loss:0.1372, mae:0.2402
Epoch: 17: loss:0.1361, mae:0.2391
Epoch: 18: loss:0.1359, mae:0.2385
Epoch: 19: loss:0.1341, mae:0.2365
Epoch: 20: loss:0.1331, mae:0.2355
Epoch: 21: loss:0.1327, mae:0.2348
Epoch: 22: loss:0.1312, mae:0.2336
Epoch: 23: loss:0.1290, mae:0.2316
Epoch: 24: loss:0.1299, mae:0.2319
Epoch: 25: loss:0.1289, mae:0.2310
Epoch: 26: loss:0.1277, mae:0.2299
Epoch: 27: loss:0.1275, mae:0.2298
Epoch: 28: loss:0.1266, mae:0.2286
Epoch: 29: loss:0.1272, mae:0.2290
Epoch: 30: loss:0.1250, mae:0.2271plt.plot(losses)
plt.show()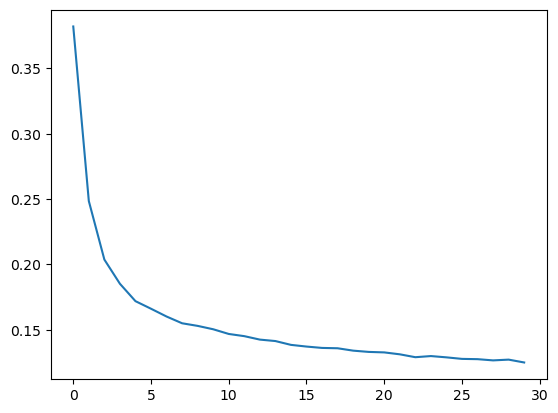
샘플링

학습된 모델을 이용해서 샘플링 알고리즘을 따라 모든 시간 단계에 대한 샘플을 샘플링합니다.
샘플링 과정에서 사용할 \(\beta_t\), \(\alpha_t\), \(\bar\alpha_t\)를 클래스 외부 변수로 빼둡니다.
alpha = MyDataset.alpha.to(device)
alpha_bar = MyDataset.alpha_bar.to(device)
beta = MyDataset.beta.to(device)
T = MyDataset.T# 샘플링 단계동안 생성된 이미지를 일정 간격마다 저장할 리스트를 준비
interval = 20 # 20 시간 단계마다 한장씩 생성 결과 기록
X = [] # 생성 이미지 저장
saved_frame = [] # 이미지를 저장한 시간 단계를 저장
N = 5 # 모델에 입력할 샘플 개수
# 최초 노이즈 샘플링
x = torch.randn(size=(N, C, H, W)).to(device)
for t in range(T, 0, -1):
if t > 1:
z = torch.randn(size=(N,C,H,W)).to(device)
else:
z = torch.zeros((N,C,H,W)).to(device)
t_torch = torch.tensor([[t]]*N, dtype=torch.float32).to(device)
eps_theta = model(x, t_torch)
x = (1 / torch.sqrt(alpha[t])) * \
(x - ((1-alpha[t])/torch.sqrt(1-alpha_bar[t]))*eps_theta) + torch.sqrt(beta[t])*z
if (T - t) % interval == 0 or t == 1:
# 현재 시간 단계로 부터 생성되는 t-1번째 이미지를 저장
saved_frame.append(t)
x_np = x.detach().cpu().numpy()
# (N,C,H,W)->(H,N,W,C)
x_np = x_np.transpose(2,0,3,1).reshape(H,-1,C)
x_np = ((x_np - x_np.min()) / (x_np.max() - x_np.min())).clip(0,1)
X.append( x_np*255.0 ) # 0 ~ 1 -> 0 ~ 255
X = np.array(X, dtype=np.uint8)샘플링 과정동안 수집한 이미지를 애니메이션으로 표현합니다.
plotly로 애니메이션을 표시하는 예제 코드는 이곳 https://plotly.com/python/animations/과 이곳 https://plotly.com/python/imshow/을 참고 하여 작성하였습니다.
fig = go.Figure(
data = [ go.Image(z=X[0]) ],
layout = go.Layout(
# title="Generated image",
autosize = False,
width = 800, height = 400,
margin = dict(l=0, r=0, b=0, t=30),
xaxis = {"title": f"Generated Image: x_{T-1}"},
updatemenus = [
dict(
type="buttons",
buttons=[
# play button
dict(
label="Play", method="animate",
args=[
None,
{
"frame": {"duration": 50, "redraw": True},
"fromcurrent": True,
"transition": {"duration": 50, "easing": "quadratic-in-out"}
}
]
),
# pause button
dict(
label="Pause", method="animate",
args=[
[None],
{
"frame": {"duration": 0, "redraw": False},
"mode": "immediate",
"transition": {"duration": 0}
}
]
)
],
direction="left", pad={"r": 10, "t": 87}, showactive=False,
x=0.1, xanchor="right", y=0, yanchor="top"
)
], # updatemenus = [
), # layout = go.Layout(
frames = [
{
'data':[go.Image(z=X[t])],
'name': t,
'layout': {
'xaxis': {'title': f"Generated Image: x_{saved_frame[t]-1}"}
}
} for t in range(len(X))
]
)
################################################################################
# 슬라이더 처리
sliders_dict = {
"active": 0, "yanchor": "top", "xanchor": "left",
"currentvalue": {
"font": {"size": 15}, "prefix": "input time:",
"visible": True, "xanchor": "right"
},
"transition": {"duration": 100, "easing": "cubic-in-out"},
"pad": {"b": 10, "t": 50},
"len": 0.9, "x": 0.1, "y": 0,
"steps": []
}
for t in range(len(X)):
slider_step = {
"label": f"{saved_frame[t]}", "method": "animate",
"args": [
[t], # frame 이름과 일치해야 연결됨
{
"frame": {"duration": 100, "redraw": True},
"mode": "immediate",
"transition": {"duration": 100}
}
],
}
sliders_dict["steps"].append(slider_step)
fig["layout"]["sliders"] = [sliders_dict]
################################################################################
fig.show()위 그림에서 play를 누르거나 슬라이드 바를 이동 시키면 시간 단계에 따라 노이즈가 제거되는 이미지를 확인할 수 있습니다. 완전히 깨끗하고 정교하게 노이즈가 제거되진 않지만 무작위 노이즈로부터 게임 아이템과 캐릭터 처럼 생긴 물체들이 약 200단계에서부터 서서히 생겨나는것을 확인할 수 있습니다!
간단한 네트워크로 충분히 납득할만한 결과를 생성할 수 있었습니다. 이제 여러분들이 네트워크를 더 정교하게 다듬어 생생한 캐릭터 이미지를 생성하시기 바랍니다.
다음편 예고
디퓨전 모델은 생성되는 이미지가 다양해야하는 문제와 이미지의 품질 문제를 잘 해결하지만 이미지를 생성하는데 시간이 오래 걸린다는 단점이 있습니다. 지난 두 편의 글을 통해 DDPM을 잘 이해 했다면 이제 샘플링 속도를 빠르게 하는 방법에 대해서 알아볼 차례입니다.